










Posle euforije ali i straha koji su obuzeli svet sa pojavom ChatGPT-ja, godinu dana kasnije, stiže i prvi veliki regionalni jezički model sa 7 milijardi parametara – YugoGPT. Njegov tvorac Aleksa Gordić za Internet portal RTS-a otkriva šta sve budući korisnici mogu da očekuju od njega.
Aleksa Gordić je završio elektroniku na Elektrotehničkom fakultetu u Beogradu 2017. godine, nakon čega je od 2018. do 2021. radio kao softverski inženjer i inženjer za mašinsko učenje u „Majkrosoft razvojnom centru” u Srbiji na HoloLens projektu u oblasti kompjuterske vizije. Posle toga radio je u najboljoj svetskoj kompaniji za veštačku inteligenciju, Guglovom Dip majndu, na jezičkim modelima koji takođe mogu da razumeju sliku i video.
Na svom Jutjub kanalu uči druge o veštačkoj inteligenciji, gde kao i na Linktinu (LinkedIn) i Tviteru (sada: Iks) okuplja veliku zajednicu. Posle iskustva u najvećim svetskim kompanijama odlučio je da svoje znanje iskoristi za stvaranje najvećeg regionalnog generativnog jezičkog modela YugoGPT-ja.
Trenirate generativni jezički model za srpski, hrvatski, crnogorski i bosanski koji ste nazvali YugoGPT. Da li ste pionir u tome?
Trenutno ne postoje opensors ili generalno javno dostupni veliki jezički modeli koji dobro rade za „naše” jezike. Pod javno dostupnim mislim na jezičke modele koji nemaju permisivnu licencu, već se mogu koristiti isključivo za istraživačke, ali ne i za komercijalne projekte. Mi čak ni to nemamo. ChatGPT poprilično lepo radi za srpski, ali je problem što vi nemate pristup modelu koji se krije iza te usluge. Ovo je veliki problem za kompanije kojima su njihovi podaci jako vredni i, koje zbog privatnosti i bezbednosti, ne smeju i ne žele da šalju na američke apije poput ChatGPT-ja.
Moj model je trenutno najbolji jezički model za srpski, bosanski, hrvatski i crnogorski jezik. Pokazao se kao bolji i od Llama 2 modela koji je Meta (nekadašnji Fejsbuk) napravio, kao i od Mistralovog 7B jezičkog modela, pri čemu je Mistral junikorn startap koji vredi dve milijarde dolara, dok je Meta kompanija koja vredi skoro trilion dolara.
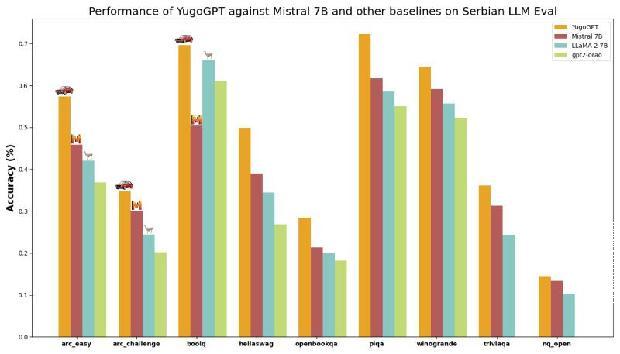
Poređenje yugoGPT-a sa drugim jezičkim modelima
Šta konkretno podrazumeva treniranje jezičkog modela, koja znanja i resursi su za to potrebni?
Treniranje jezičkog modela podrazumeva prikupljanje ogromne količine teksta sa interneta i potom propuštanja tog teksta kroz džinovske neuronske mreže na stotinama, nekada čak i hiljadama grafičkih kartica. Sve ovo traje nedeljama, a nekada i mesecima i tokom tog procesa neuronska mreža uči kako da izvuče zanimljive paterne iz teksta. Ona uči gramatiku i sintaksu jezika, uči kako da broji, kako da sažme tekst i razne druge veštine.
Za treniranje ovako jednog kompleksnog sistema je potrebno dosta veština koje su u globalnoj oskudici, i zato na ovakvim projektima uglavnom rade desetine eksperata. Dobro znanje matematike, softverskog inženjerstva, razumevanja NLP-a, obrade podataka, vizualizovanja podataka, itd. U ovom slučaju ja imam podosta iskustva, iz dosta različitih oblasti, pa sam sposoban da sve to i sam odradim, ali naravno bilo bi lakše, bolje i brže sa većim timom i više novca. Takođe, neophodan je pristup desetinama GPU-ova da bi se ovakav sistem istrenirao u doglednom vremenu.
Šta će moći da „radi” YugoGPT?
Ukoliko ste upoznati sa funkcionalnostima ChatGPT-ja, YugoGPT će imati slične sposobnosti. Dodatno, pošto će pojedinci i kompanije imati pristup parametrima modela, to omogućava veću fleksibilnost, pa se od njega može napraviti ekspert za finansije, poreze, psihologiju, i slično naravno uz kuriranje izlaza iz modela u slučaju osetljivih aplikacija.
Sa tehničke strane, model možete da kvantizujete – i time napravite manjim. Samim tim kompanije mogu da uštede novac. Ovim gubite nešto na preciznosti modela, ali bitna stavka je da vi imate tu kontrolu, tu polugu, i odlučujete šta ima najviše smisla za vas i vaš biznis, umesto da to OpenAI odlučuje za vas.
Zašto treba razvijati regionalne ekosisteme?
Postoji više razloga zašto je ovo jako bitno: kulturološki – u vreme gde veštačka inteligencija i digitalni sistemi generalno postaju deo svakodnevnice sa kojima naša deca interaguju, želite sisteme koji pričaju vaš jezik i poznaju vašu kulturu, kako ih ne biste izgubili. Tehnički – ova tehnologija rešava probleme koji su doskora bili izvan dometa tadašnje tehnologije, takoreći deo naučne fantastike. Ekonomski – kao posledica rešavanja nekih klasa problema otključavaju se novi izvori prihoda, nova vrednost za lokalni ekosistem, za korisnike kao i za kompanije i startape.
Za šta sve mogu da se istreniraju veliki jezički modeli?
Glavna osobina ovih sistema je da su generalni, tako da je odgovor na ovo pitanje – za sve za šta mogu i ljudi kada im date pristup tastaturi. LLM sam po sebi nema fizičko telo, tako da ga to ograničava samo na svet elektrona, ali istraživači i inženjeri rade naporno svaki dan da reše i te tipove privremenih ograničenja.
Kada očekujete da će YugoGPT biti spreman?
Treniranje osnovnog modela je završeno. Trenutno sam u procesu pripreme jednostavne veb aplikacije gde će ljudi moći da se igraju sa YugoGPT-jem. Nešto nalik na ChatGPT interfejs na koji su navikli, samo su stvari na srpskom. Demo stiže, nadam se, već sledeće nedelje, a nakon toga planiram i da opensorsujem model nakon što sam uradio dovoljno testova i postarao se da je model bezbedan za širu upotrebu u našem regionu.
Radili ste u Guglu, Dip majndu… Koliko Vas je iskustvo rada u tim velikim kompanijama opredelilo da osmislite i krenete u ovako obiman projekat?
Rad u tim kompanijama i, paralelno, moj konstanti rad na sebi i van posla na svojim personalnim projektima, pomogao mi je da uvidim važnost ovih sistema i da razumem koliko će ključnu ulogu odigrati u godinama koje dolaze. Takođe mi je pomoglo da steknem znanja da treniram ove sisteme. Na kraju, primetio sam da je većina tehnološkog sveta fokusirana skoro isključivo na engleski i vidim ogromnu priliku da napravim moćne i korisne sisteme i za druge jezike, a gde bolje da počnem nego od svog maternjeg jezika.
Ulaganja u ovakav projekat nisu mala, koliko je tu značajna podrška zajednice i društva u celini?
YugoGPT je treniran na 16 A100 grafičkih kartica koje je sponzorisala kompanija TogetherAI. Ja sam dobro povezan u svetu VI pa sam uspeo to da dobijem „besplatno“ jer je projekat opensors. Tako da tu konkretno probleme sa strujom nisam imao. Kažem „besplatno“ jer zbog moje velike zajednice ta kompanija ima šta da dobije zauzvrat – naime marketing i takozvanog power user sistema koji može da dâ vredan fidbek oko njihovih sistema, što kompanije žele da plate.
Prethodni projekat koji sam razvijao, koji se ticao mašinskog prevođenja, je treniran isključivo na mom kompjuteru i to je letos napravilo prilično zanimljive račune. Taj model ima „samo“ 615 miliona parametara pa može da se trenira na manje grafičkih kartica. Takođe, vredno je spomenuti da je prethodnih nekoliko nedelja više pojedinaca, kao i nekoliko kompanija, potpomoglo projekat finansijski, za šta sam im jako zahvalan! Oni su „mecene“ ili pokrovitelji projekta.
Koliko je značajno objediniti znanja i okupiti stručnjake iz različitih oblasti za stvaranje “srpskih” modela?
Zbog prirode ovih sistema najviše nam treba IT stručnjaka u oblasti mašinskog učenja, kao i softverski inženjeri, ali su i ostali domenski eksperti od velike pomoći kada se radi evaluacija ovih sistema. Oni mogu da interaguju sa sistemom i primete greške i nedostatke. Srećom, stvarno bilo ko kome je maternji jezik srpski takođe može da doprinese, VI demokratizuje pristup i omogućava da i ljudi koji nisu eksperti takođe značajno mogu da doprinesu.
Smatram da je ove stvari teško organizovati od strane države i moraju da se dešavaju, što spontano, što kroz akademsku zajednicu, kroz ljude kojima je ovo hobi, kao i kroz industriju. Ali država svakako može da pomogne – recimo finansijski, ali to treba uraditi jako pažljivo da se progres ne bi usporio.
Da li je ova inicijativa dobar podstrek za otvaranje domaćih startapa u ovoj oblasti i koju bi ulogu trebalo da odigra država kako bi, osim na nivou strategije, pomogla i osnažila razvoj domaćih projekata?
Apsolutno mislim da je odgovor da. Ja takođe pokrećem svoj startap, RunaAI, gde ću kompanijama nuditi moćne, personalizovane sisteme koji rešavaju razne probleme u oblasti obrade teksta. Ideja moje kompanije je da razvija jezičke modele koji podržavaju razne jezike, a ne samo engleski, i odlučio sam da će mi početna tačka biti srpski i ostali regionalni jezici.
Mišljenja sam da država treba da se fokusira na sledeće stvari: Izgradnja moćnog nacionalnog superkompjutera. Znam da imamo platformu u Kragujevcu, ali sam ja već kao pojedinac uspeo da dobijem više kompjutera i bez dizanja novca iz fondova. Kada budem podigao takozvani „seed round“ verovatno ću imati na raspolaganju stotine GPU-ova. Tako da tu postoji još dosta prostora za napredak. Neke severne zemlje poput Finske su uvidele koliko je ovo značajno pa su izgradili svoj superkompjuter LUMI. Postoji još mnogo primera u Evropi i u svetu. Teško mi je da iskažem koliko je ovo bitno za našu državu.
Hitno ulaganje u modernizovanje nastavnih programa vezanih za veštačku inteligenciju. Uveo bih da se ovo radi već od osnovne škole kao obavezan predmet. Nažalost, deluje mi da čak i naši najbolji fakulteti poput ETF-a još nisu ni blizu gde bi trebalo da budu u 2023. godini. Ovo drastično mora da se promeni.
Pomoć oko pravljenja velikih datasetova za srpski jezik, i to ne samo tekstualnih. Za ostalo treba pratiti američki model i pustiti da privatne kompanije i potrebe korisnika pokrenu tržište. Subvencije daju loš podsticaj i možda kontraintuitivno usporavaju progres. Dobar primer je raketna industrija u SAD i dinamika između Spejs iksa i Nase.

















